常見統計分析相關文獻引用大全(陸續增加中)

文章目錄
零、前言
書寫論文時,絕不是自己自吹自擂、自作主張就可以矇混過關,「引經據典」是必要的,國內有關統計分析的書籍數量不少,這些工具書不但具有統計指引的功能,也是引用統計觀念與作法進入論文的好素材,像是預試問卷到底要幾份?量表至少要有幾個構面?項目分析包含哪些項目?刪除不適宜題項的標準為何?該採用探索性因素分析還是驗證性因素分析?結構方程模型的參數標準為何?在以下皆可找到相關文獻,加思揚將之整理出來,起初是為了自己,如今與有緣的研究者共享之,期待節省大家搜尋統計分析相關文獻的時間,寫出一本有品質的好論文。
壹、統計科普
林清山(2001)。心理與教育統計學。東華。
統計學可分描述統計、推論統計和實驗設計三大類(林清山,2001,p1)。
變數或譯為變項、變因,是指可依不同的數值或類別出現的屬性,其相反詞是常數。變數可有下列分法:自變數、依變數,連續變數、間斷變數,名義變數(類別變數)、次數變數、等距變數、比率變數,量的變數、質的變數(林清山,2001,p1)。
算術平均數簡稱「平均數」,常以M來代表,當我們蒐集到的統計資料是屬於連續變數時,最宜使用算術平均數的統計方法來處理。幾何平均數常簡寫為GM,可以用來表示平均改變率、平均生長率和平均比率。有些教育或心理學方面的現象是依照幾何級數而改變的,這類現象的統計資料用一般算術平均數並不恰當。調和平均數以HM來代表,當我們要算出幾個速率的平均數時最常使用它(林清山,2001,p39、p49~51)。
變異量數是用來表示團體中各分數之分散情形的統計數,亦即是用來表示個別差異大小的指標,其中最常用者為標準差(林清山,2001,p53)。
常態分配時,平均數上下一個標準差之間的人數約佔總人數之68%,兩個標準差之間
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
從統計學的原理來分析,1000人所獲得的意見調查,抽樣誤差約為3%。目前許多民意調查機構多以容許正負三個百分點來進行調查,其樣本數即需大於1000人(邱皓政,2015)。
變異(variety)是統計的根本,而測量與統計是一門研究變異的科學(邱皓政,2015)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
張偉豪(2011)。SEM論文寫作不求人。鼎茂。
統計的基礎在於變異數,沒有變異就沒有統計。一個變數的變異數愈大,代表受測者之間的意見愈分歧,因此找出那些原因可以有效的解釋這些變異,便是統計的工作(張偉豪,2011,p16)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳正昌(2013)。SPSS與統計分析。 五南。
SPSS統計軟體由SPSS公司於1968年設立,並發行第1版,SPSS在2009年7月被IBM公司併購,早期SPSS代表Statistical Package for the Social Sciences,後來改為Statistical Product and Service Solutions的縮寫,2009年4月曾短暫更名為PASW(Predictive Analytics Software),目前正式名稱為IBM SPSS Statistics(陳正昌,2013,p003)。
在資料處理中,我們常說「垃圾進,垃圾出」(garbage in, garbage out),如果數據不經過爬梳整理就直接分析,所得結果常常不能盡信。因此,確保所用數據正確無誤,是資料分析過程中相當重要的步驟(陳正昌,2013,p087)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
陳寬裕、王正華(2021,p048)認為問卷與量表的差異主要有四:一、量表需要理論的依據,問卷則只要符合主題即可;二、量表的各分量表都要有明確的定義,問卷則無此要求;三、量表以各分量表為單位來計分,問卷是以各題為單位來計次;四、量表的計算單位是分數,而問卷的計算單位通常是次數。
在常態分配中,資料分布概況具有以下特性:95%的個體會落在分配平均數±1.96個標準差的區間內,99%的個體會落在分配平均數±2.58個標準差的區間內(陳寬裕、王正華,2021,p048)。
在敘述統計學中,母體的統計特徵一般稱為參數(如母體平均數),而樣本的統計特徵則稱之為統計量(如樣本平均數)。一般而言,母體參數通常為未知數,因母體太大,無法探究其確實數據,而樣本統計量只要經由抽樣完成,通常就可以算出其值(陳寬裕、王正華,2021,p309)。
推論統計學的價值在於藉由低成本方式取得的樣本資料之統計量來推論母體參數,更精準的論述為推論統計學能在樣本資料進行描述性分析的基礎上,以機率的方式對統計母體的未知特徵進行推論(陳寬裕、王正華,2021,p309)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
其他
APA:美國心理學會(American Psychological Association),很煩人的APA格式就是從這裡來的(笑),目前(2023年1月)最新版本是第七版。

貳、樣本數
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
以因素分析為例,樣本數約為題數的10倍,一個50題的量表,即須500人樣本,如此才能獲致較為穩定的統計分析數據(邱皓政,2015)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
陳寬裕、王正華(2021,p206)引用國外學者觀點,要進行探索性因素分析時,樣本的大小可遵照兩個原則:1.題項數與受訪者的比例最好在1:5以上,即樣本數須為題項數的五倍以上;受訪者的總數不得少於100人。

參、問卷設計
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
Likert-type(李克特式)量表是廣泛應用在社會與行為科學研究的一種測量格式,適合於態度測量或意見的評估。典型的Likert-type量表由一組測量某一個相同特質或現象的題目所組成,每一個題目均具有相同的重要性。為使受測者的感受強度能夠被適當的反映在Likert-type量尺的不同選項,過多的選項並無助於受測者進行個人意見的表達,過少的選項則會損失變異量與精密度,因此除非特殊的考量,一般研究者多選用4、5、6點之Likert-type量尺。採用偶數格式的時機,多為研究者希望受測者有具體的意見傾向,避免回答中間傾向的意見(邱皓政,2015)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
張偉豪(2011)。SEM論文寫作不求人。鼎茂。
張偉豪(2011,p43)統整國內外學者看法,認為問卷設計有七個注意要點:1.量表最好為七點尺度;2.每個潛在構面至少要有三個題目,五~七題為佳;3.每一指標不得橫跨到其他潛在因素上;4.問卷最好引用自知名學者提出的理論作修正;6.模型主要構面維持在五個以內,不要超過七個;7.模型中潛在因素至少應為兩個。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
邱皓政(2015)認為量表的項目分析可分為質的分析與量的分析,質的分析主要針對量表項目的內容與形式的適切性討論,量的分析則主要對試題的鑑別度進行檢驗。

肆、預試分析(項目分析)
邱皓政(2015)認為量表的項目分析主要對試題的鑑別度進行檢驗,透過相關分析法、極端組檢驗法、題目總分相關法等量化指標對量表每個試題進行鑑別度檢驗。極端組檢驗法係將預試樣本在該量表總分的高低,取極端的27%分為高低二組,然後計算個別的題目,在兩個極端組的得分平均數,一般進行極端組檢驗法之t檢定時,為了避免過度拒絕的問題發生,所使用的標準可用CR(t值)≧2.58表示具有良好鑑別度;除了極端組檢驗法,SPSS軟體提供一項校正項目總分相關係數,係指每一個題目與其他題目加總的總分(不含該題目本身)的相關係數,一般的要求相關係數要在.30以上。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
張偉豪(2011)。SEM論文寫作不求人。鼎茂。
藉由預試問卷的分析,瞭解問卷是否具鑑別力,亦即問卷是否能產生足夠的變異,以供事後的統計分析。如果受測者的回答過於集中,會造成變異太小,亦即該題目沒有適當的鑑別力,應在正式問卷中刪除,以達問卷精簡的目的(張偉豪,2011,p15)。
項目分析又稱題項鑑別力分析,主要目的在於求出問卷個別題項之決斷-CR值,以便將未達顯著水準的題項刪除,除了可事先刪除不具鑑別力的題目亦可提高問卷的效度(張偉豪,2011,p15)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
涂金堂(2012)。量表編製與SPSS。五南。
預試量表的項目分析經常使用決斷值的評判方式,所謂決斷值,即是以高分組與低分組受試者在該題的得分情形進行獨立樣本t考驗,高低分組可採用總分最高分前27%為高分組,總分最低分後27%為低分組,當該題沒有顯著性差異時,顯示該題不具有鑑別效果,顯示該題可能是不良題目(涂金堂,2012)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
吳明隆、張毓仁(2011)。SPSS(PASW)與統計應用分析I、II。五南。
吳明隆、張毓仁(2011)指出,量表各構面的α係數最好在.70以上,如果是在.60以上勉強也可以接受。而總量表的α係數最好在.80以上,如果在.90以上則信度更佳。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
陳寬裕、王正華(2021,p163)認為信度是指當研究者針對某一群固定的受測者,利用同一種特定的測量工具,在重複進行多次測量後,所得到結果的相似除度。因此,信度除了具有重複測量時所需具備的穩定性特質外,尚具有一致性的含意。
效度代表測量工具之正確性和準確性的程度,也就是測量工具確實能測出其所欲測量的特質、特徵或功能之程度。常見的效度有四種類型:表面效度、內容效度、效標效度與建構效度,表面效度指測量工具經由受測者或研究者主觀覺得其諸多題項與研究主題相關的程度;內容效度指某測量工具之題項內容是否周延、具代表性、適切性,並確實已包含所欲測量主題的內涵;效標效度意指用某些標準或效標來精確的指名一個構念,檢測測量指標的效標效度時,是要將它與其他測量同一構念且研究者有信心的指標(即效標)來進行比較,通常會以測量指標的得分和效標得分間的相關係數來檢驗效標效度程度之高低;建構效度係指測量工具的內容是否能夠測量到理論上的構念或特質的程度(陳寬裕、王正華,2021,p186、p187、p188)。

伍、探索性因素分析與驗證性因素分析
涂金堂(2012)。量表編製與SPSS。五南。
涂金堂(2012)亦認為當量表編製是以堅實的理論作為依據,即可省略探索性因素分析,直接進行驗證性因素分析,檢驗編製的量表是否符合理論。故挑選別人已編輯好的量表作為自己的研究工具時,較理想的方式是直接以該量表來進行驗證性因素分析,而非再重新進行一次探索性因素分析。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳正昌(2013)。SPSS與統計分析。 五南。
陳正昌(2013,p683、p703)認為試探性因素分析主要用來分析題目背後的構念,如果研究者在編製量表時,並無明確之理論依據或是預設立場,或是以往僅有少數的相關研究,則使用試探取向的因素分析會較恰當。而如果研究者在編製量表時,已有明確之理論依據或是預設立場,或已經有許多相關研究,則使用驗證取向的因素分析會較恰當。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
吳明隆(2019)。結構方程式:AMOS的操作與應用。五南。
吳明隆(2019,p349)認為依使用目的而言,因素分析可分為「探索性因素分析」(EFA)與「驗證性因素分析」(CFA),EFA與CFA兩種分析方法最大的不同在於測量理論架構在分析過程中所扮演的角色與檢定時機。就EFA而言,測量變項的理論架構是因素分析後的產物,因素結構是從一組獨立測量指標或題項間,由研究者主觀判斷所決定的一個具有計量合理性與理論適切的結構,並以該結構來代表所測量的概念內容或構念特質,即理論架構的出現是在EFA程序中是一個事後概念;相對之下,CFA的進行則必須有特定的理論觀點或概念架構作為基礎,然後藉由數學程序來確認評估該理論觀點所導出的計量模式是否適當、合理,因此理論架構對CFA的影響是在分析之前發生的。
在量表或問卷編製的預試上,都會先以探索性因素分析,不斷的嘗試,以求得量表最佳的因素結構,以建立問卷的建構效度(吳明隆,2019,p349)。

陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
陳寬裕、王正華(2021,p189)認為探索性因素分析屬於多變量統計分析技術的一種,其主要目的是濃縮、簡化資料,研究如何以最少的資訊遺失,而能把眾多的觀測變數(題項)濃縮成少數幾個具代表性的因素之統計技術。
主成分分析法實際上是一種獨立於探索性因素分析外的一種資料簡化技術,它的作法是將所蒐集到的各觀測變數(題項)之資料予以歸納,找出一個最能夠解釋各觀測變數之因素,主成分分析法在因素分析中占有重要的地位,也是探索性因素分析中用於脆取出共同因素的主要分析方法(陳寬裕、王正華,2021,p200、p201)。
進行探索性因素分析時,通常會選取累積總解釋變異量(%)達50~80%時的因素個數為研究中所欲萃取出的因素個數(陳寬裕、王正華,2021,p202)。
陳寬裕、王正華(2021,p203)綜合探索性因素分析因素萃取與題項選擇的準則整理如下:1.因素之特徵值須大於1;2.累積總解釋變異量不得小於0.5;3.共同性須大於0.5;4.某原始變數同時橫跨兩因素時,可視該原始變數在兩因素上的負荷量大小而決定,若兩因素負荷量的差大於0.3時,則排除較小者;5.該因素題項的因素負荷量絕對值大於0.5者。
陳寬裕、王正華(2021,p206)引用國外學者觀點,要進行探索性因素分析時,樣本的大小可遵照兩個原則:1.題項數與受訪者的比例最好在1:5以上,即樣本數須為題項數的五倍以上;受訪者的總數不得少於100人。
陳寬裕、王正華(2021,p234)認為進行探索性因素分析時,仍難免會有一些現存的題項,共同性太低(低於0.3)、因素負荷量太低(低於0.5)或無法被任何因素所解釋。在這些情形下,研究者有必要將此類題項排除於量表之外,再一次進行因素分析,如此不斷地遞迴,直到所有題項皆能被所萃取出來的因素解釋後,才算完成整個探索性因素分析的任務。
一般研究者於實證時所設計的問卷,大都是根據理論或文獻的原始量表而來的,如研究者進行因素分析所得到的因素結構不盡理想,這都是資料的隨機性所引起的。這時或可使用相同題項的另一組資料,並以探索性因素分析所萃取之因素結構為基礎,然後運用結構方程模型的驗證性因素分析技術來證明自己所發展出來的因素結構是具有信度、收斂效度與區別效度的(陳寬裕、王正華,2021,p234、p235)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2022)。結構方程模型:運用AMOS分析。五南。
傳統的探索性因素分析技術是一種資料導向的分析方式。也就是說,研究者會純粹的資料的角度出發,對資料進行分析以探索、發現變數關係間的本質、特徵與客觀規律。因此,探索性分析技術從抽樣調查所獲得的資料而建立變數間因素結構的相關模型。相對的,結構方程模型則屬於一種驗證性的分析技術,驗證性的分析技術會先釐清問題點、然後建立模型,最後再利用資料去驗證模型的適用性(陳寬裕、王正華,2022,p76)。
量表或調查問卷是社會、心理、管理等科學領域常用的測量工具,驗證性因素分析便是確認量表所調查資料是否能將潛在變數精確地測量出來的一種方法,而在評鑑測量模型時,我們可以將整個評鑑過程分為五個主要階段,階段一:常態性檢定,階段二:檢驗違犯估計,階段三:檢驗模型配適度,階段四:檢驗收斂效度,階段五:檢驗區別效度(陳寬裕、王正華,2022,p239)。
陳寬裕、王正華(2022,p190)認為因素分析技術可分為探索性因素分析(EFA)和驗證性因素分析(CFA)兩種。弱研究者在進行因素分析前,對於資料的因素結構並未有任何假設,僅想藉由統計數據與因素分析技術來探索、發現與確定因素的結構時,此種因素分析策略通常帶有濃厚的嘗試錯誤與主觀意識之意味。因此,即稱之為探索性因素分析。而當研究人員先根據某種理論或者其他的先驗知識對因素的可能個數或者因素結構作出假設,然後利用因素分析技術與實際的樣本資料來檢驗這個假設是否成立的辯證過程,就稱為是驗證性因素分析了。

陸、t 檢定
陳正昌(2013)。SPSS與統計分析。 五南。
獨立樣本 t 檢定旨在檢定兩群獨立樣本在某一變數之平均數是否有差異(陳正昌,2013,p281)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
單一樣本t檢定的目的在於利用抽取自母體的樣本資料,以推論該母體的平均值是否與指定的檢定值之間存在顯著差異(陳寬裕、王正華,2021,p315)。
獨立樣本t檢定的目的在於檢定抽樣自某兩個母體的獨立樣本,經計算兩獨立樣本的平均值後,推論原本的兩個母體之平均值是否存在顯著性差異(陳寬裕、王正華,2021,p320)。
成對樣本t檢定的主要目的在於檢定兩成對樣本的平均值是否存在顯著差異(陳寬裕、王正華,2021,p336)。

柒、變異數分析
陳正昌(2013)。SPSS與統計分析。 五南。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
在平均數之差異性檢定的方法選用上,若樣本資料為兩組時,一般我們會使用t檢定,若我們要檢定多個(3個以上)樣本平均數的差異是否具有統計意義時,就得使用變異數分析了(陳寬裕、王正華,2021,p351)。
在變異數分析中,我們常用一些關聯強度統計量來評估因子效果的實務顯著性,這些關聯強度統計量諸如ω2(Omega squared )、η2(Eta squared )、檢定力(power)(陳寬裕、王正華,2021,p372)等。
變異數分析的主要目的,在探討哪些因素具有造成觀測值平均數變動的效果。在二因子變異數分析中最主要的效果有兩種,一為主要效果,另一為交互作用效果。所謂主要效果是指因子(自變項)本身的變化對觀測值(依變項)所造成的影響,而交互作用效果意指兩因子(自變項)的互動關係對觀測值(依變項)所造成的影響,若交互作用效果檢定顯著,則須再更深入的進行單純主要效果檢定與事後比較(陳寬裕、王正華,2021,p403)。

捌、共變數分析
陳正昌(2013)。SPSS與統計分析。 五南。
如果使用實驗法進行研究,最重要的是確保各組一開始的條件是相同的,有時基於一些限制而不能隨機分派,只好採用原樣團體進行實驗,此稱為準實驗設計。由於無法隨機分派,因此受試者在實驗前的差異就會影響依變數,因此,在進行準實驗設計之前,一般會先實施前測,以了解實驗前各組的基準點,在經過一段時間的實驗之後,再實施後測。進行統計分析時,會將前測當成共變量,而用後測為依變數,自變數則是不同的組別,進行共變數分析,共變數分析在於排除共變量的效果後,分析自變數對依變數的效果(陳正昌,2013,p475、p478)。

玖、相關分析
陳正昌(2013)。SPSS與統計分析。 五南。
兩變數之間有相關,不代表就有因果關係,因此不可做因果關係的推論(陳正昌,2013,p548)。
典型相關是Pearson積差相關的擴展,在於分析兩組量的變數間之關聯程度。假設有3個X變數與4個Y變數,要計算它們之間的關係,最常使用的統計方法就是典型相關(陳正昌,2013,p581)。
INCLUDE ‘C:\Program Files\IBM\SPSS\Statistics\22\Samples\English\Canonical correlation.sps’.(註1)
CANCORR SET1=Locus Concept Motivation/ (註2)
SET2=Read Write Math Science/. (註3)
MANOVA aa ab ac ad WITH ba bb bc bd
/PRINT=SIGNIF(EIGN DIMENR)
/DISCRIM=RAW STAN COR ALPHA(1.0)
/DESIGN.
(陳正昌,2013,p591)
註1:22為SPSS版本數字。
註2:Locus Concept Motivation為研究者在SPSS自訂之變數構面名稱。
註3:Read Write Math Science為研究者在SPSS自訂之變數構面名稱。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
吳明隆(2019)。結構方程式:AMOS的操作與應用。五南。
吳明隆(2019:p797)認為典型相關分析(CCA)為多變量統計方法之一,它包含了母數統計法與無母數統計法(卡方分析),其他母數統計法均為典型相關分析的特例。且吳明隆引用國外學者對結構方程模式分析的觀點而言,典型相關分析為結構方程模式的一個特例,且SEM優於CCA之處有二:一為SEM可對加權係數、結構係數與跨典型負荷係數作顯著性的檢定,二為SEM可對每一個典型相關係數作顯著性之考驗,其方法較CCA之檢定方法更為嚴謹。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
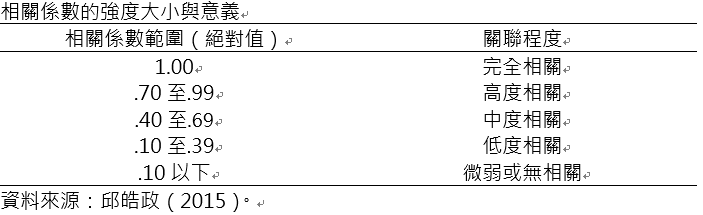
陳寬裕、王正華(2021,p243)認為相關分析的主要目的在於探討變數之間關係的緊密程度,反應變數之間緊密程度的指標主要就是相關係數,樣本的相關係數一般用「r」來表示,相關係數的取值在-1和+1之間,當數值越接近-1或+1時,則表示關係越緊密。但是相關係數是根據樣本的資料計算的,因此若想要確定母體中兩個變數是否也相關時,應該要考慮到樣本規模的影響力,因為樣本太小,推論時可能會出現較大的誤差。
偏相關分析就是「在研究兩個變數之間的線性相關關係時,控制可能對其間關係產生影響的變數」之相關分析方法(陳寬裕、王正華,2021,p270)。
在社會、經濟、心理及教育等眾多領域中,研究者經常會遇到需要研究多個隨機變數與其他多個隨機變數之間的相關性問題,此時簡單相關係數或偏相關係數可能就有點黔驢技窮,這時就需要用到典型相關分析技術了(陳寬裕、王正華,2021,p607)。

拾、迴歸分析
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析。五南。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳正昌(2013)。SPSS與統計分析。 五南。
迴歸分析的功能有二:一為解釋,二為預測。解釋的功能主要在於說明兩變數間的關聯強度及關聯方向;預測的功能則是使用迴歸方程式,利用已知的自變數來預測未知的依變數。建立迴歸模型時,很少只用一個預測變數,而會使用兩個以上的預測變數,以更準確預測效標變數,此時稱為多元迴歸分析(陳正昌,2013,p603、p625)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華。論文統計分析實務:SPSS與AMOS的運用。五南。
簡單線性迴歸模型主要是研究兩個變數之間的關係,然而實際的客觀現象可能會比較複雜,因此在進行迴歸預測時,如果能盡可能的全面性考量到各種因素的影響,那麼預測的效果會更好一些,故而我們有時也會遇到要研究兩個以上之自變數的迴歸問題,這種迴歸問題一般即稱為多元迴歸分析(陳寬裕、王正華,2021,p531)。
多元迴歸模型可能會有存在共線性問題,共線性意指在自變數中有兩個或兩個以上的自變數存在完全線性或幾乎完全線性的關係,要解決共線性的問題,主要採用剔除變數的方法,可採用允差值(tolerance)、變異數膨脹係數(VIF)與條件指標(CI)等技術指標來確定引起共線性問題的變數(陳寬裕、王正華,2021,p534)。
階層迴歸分析的特色在於能將自變數依特定理論分為數個區組而投入迴歸模型,如果各區組自變數投入的方式採強迫進入法,那麼屬解釋用途的應用;如果結合逐步迴歸方法、刪除法、向後法與向前法等方法,則屬預測用途的迴歸模型(陳寬裕、王正華,2021,p577)。

拾壹、IPA分析
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
重要度-表現分析法(簡稱IPA)被認為是評估服務品質及發展管理策略的有效工具,且已被廣泛使用於觀光、餐飲、休閒遊憩、教育、保健等領域的服務品質研究。IPA法為一種藉由評估各產品/服務之屬性的重要度和表現績效,以於座標平面上標示出各產品/服務屬性之相對位置,進而針對這些產品/服務屬性提出改善優先順序策略的技術(陳寬裕、王正華,2021,p147)。

拾貳、結構方程模型(SEM)
黃芳銘(2009)。結構方程模式-理論與應用。五南。
結構方程模式之所以能夠是一種全包式統計的方法論乃是因為融合了因素分析以及徑路分析兩種統計技術(黃芳銘,2009,p5)。
SEM體系可以分為兩個次體系:測量模式次體系與結構模式次體系(黃芳銘,2009,p8)。
使用觀察變項來建構潛在變項的模式就是測量模式,也就是用觀察變項來反應潛在變項,測量模式在SEM的體系裡就是一般所稱的驗證性因素分析模式,也就是說,在SEM中的驗證性因素分析的技術是用於評鑑觀察變項可以定義潛在變項的程度(黃芳銘,2009,p8)。
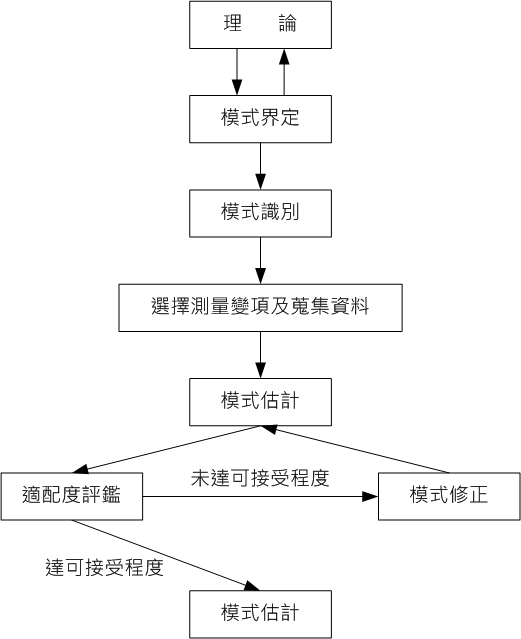
(黃芳銘,2009,p28)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
張偉豪(2011)。SEM論文寫作不求人。鼎茂。
SEM是一種大樣本的分析技術,樣本數不應該太小,而且執行SEM如無特殊原因,一般均以內定的最大概似法進行,而最大概似法在樣本大於500以上時,卡方值會嚴重的膨脹,導致模型配適不佳。綜合國外專家學者的看法與經驗法則,樣本要大於200並小於500是合理的樣本數(張偉豪,2011,p28)。
結構方程模型(Structural Equation Modeling,SEM)分析是系統性分析的典型應用,包含許多變數的線性模型整合。模型中包括了測量變數與潛在變數之間的關係,及直接與間接效果的評估(張偉豪,2011,p37)。
SEM採取的是整體模型的評估,以樣本共變數矩陣與模型期望矩陣比較,兩者的差異愈小,表示假設模型與樣本資料愈相似,因此SEM的假設寫法只有一個,H0:樣本共變異數矩陣與模型期望矩陣沒有差異(張偉豪,2011,p39)。
結構方程模型是由因素分析結合路徑分析的一種技巧,結構方程模式的原理討論與技術發展成長迅速,逐漸成為社會與行為科學研究者必備的專門知識之一(張偉豪,2011,p56)。
SEM分析有一難以克服的缺點,亦即潛在變項共線性的問題,因為SEM分析無法像複迴歸分析提供簡易的共線性診斷訊息,如忍受值(tolerance)、變異膨脹係數(variance inflation factor,VIF)及條件指標(condition index,CI)。其主要原因為結構方程模型當中變項繁多、估計程序複雜,結構方程模型中分析的共變矩陣,所有變項相關並不能單獨處理,使得多元共線性概念顯得模糊(張偉豪,2011,p59)。
在SEM分析中,估計的方法有許多種,其中以最大概似估計法(Maximum Likelihood Estimation,MLE)是估計最常用的方法,也是所有SEM軟體內定的估計方法。除非研究人員有特殊的理由,否則MLE是目前SEM最普遍使用的估計方法(張偉豪,2011,p63)。
當我們分析驗證式因素分析或結構方程模型時,並不是每個模型都能符合研究的預期。研究人員有時需要重新改善模型配適不佳的情形,修正時可以依照理論的根據或依靠SEM軟體產生的參考指標對配適度不良的模型或不要要的估計參數加以修正,修正指標(Modification Index,MI)及標準化殘差共變異數矩陣是最適合的判定標準(張偉豪,2011,p66)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
張偉豪、鄭時宜(2012)。與結構方程模型共舞-曙光初現。前程。
張偉豪、鄭時宜(2012,p297、p298)認為模型配適度如果有改善的空間,可根據配適指標進行修正,模型修正指標(Modification Index,MI)主要是協助研究人員判斷模型是否有設定錯誤,以便進行事後修正,而MI表示模型所能減少的最少卡方值,而卡方值嚴重膨脹,導致模式配適度不佳,研究者會希望卡方值是愈小愈好,因此當然要優先考慮卡方值較大的變數。如果有兩個測量變數相關過高,產生題意雷同的情形,可考慮刪除多餘題項。
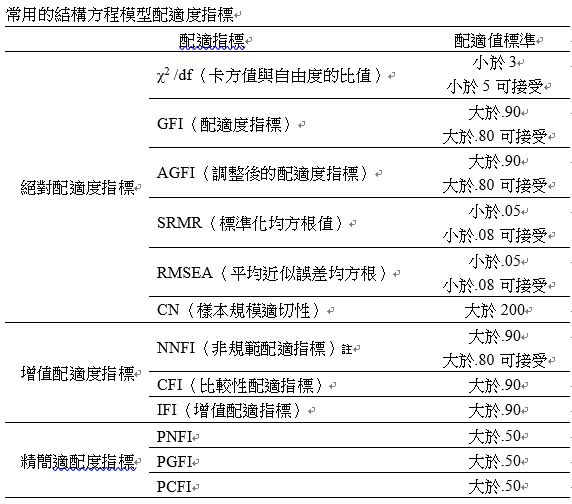
註:在Amos ModelFit報表裡面標示為TLI
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
吳明隆(2019)。結構方程式:AMOS的操作與應用。五南。
早期LISREL一詞逐漸與結構方程模式(structural equation modeling)劃上等號,但現在已有多數研究者將SEM與AMOS連結在一起,此趨勢可能受到SPSS統計套裝軟體的普及應用及SEM圖形式界面操作有關(吳明隆,2019,p3)。
SEM模式分析的基本假定與多變量母數統計法相同,樣本資料要符合多變項常態性假定,資料必須為常態分配資料,測量指標變項呈現線性關係(吳明隆,2019,p4)。
SEM基本上是一種驗證性的方法,通常必須有理論或經驗法則支持,由理論來引導,在理論導引的前提下才能建構假設模式圖(吳明隆,2019,p4)。
結構方程模型有二個基本的模式:測量模式與結構模式,測量模式由潛在變項與觀察變項組成,觀察變項又稱為潛在變項的外顯變項或測量指標或指標變項,觀察變像是量表或問卷等測量工具所得的數據,潛在變數是觀察變數間所形成的特質或抽象概念,此特質或抽象概念無法直接測量。測量模式在SEM的模型中就是一般所謂的「驗證式因素分析」(CFA),驗證式因素分析的技術是用於檢核數個測量變項可以構成潛在變項的程度。而結構模式即是潛在變項間因果關係模式的說明(吳明隆,2019,p14、p21、p25)。
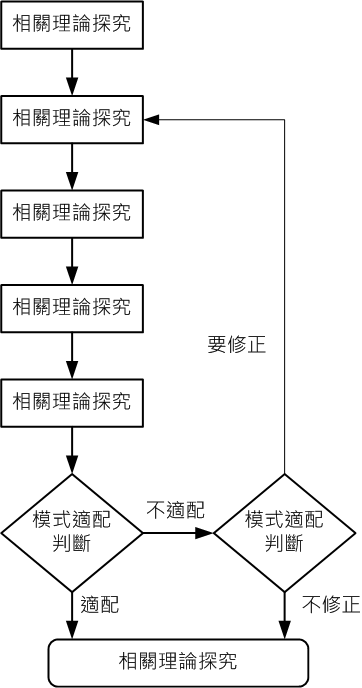
(吳明隆,2019,p50)
吳明隆(2019,p66)認為有關結構方程模式配適度的評鑑有許多不同主張,其整合國外學者較為周延的論點,整體模式適配度指標可細分為「絕對適配指標」、「相對適配指標」、「簡約適配指標」,整體模式適配度的檢核可說是模式外在品質的考驗,模式內在結構適配度的程度乃代表各測量模式的信度及效度,可說是模式內在品質的檢核。
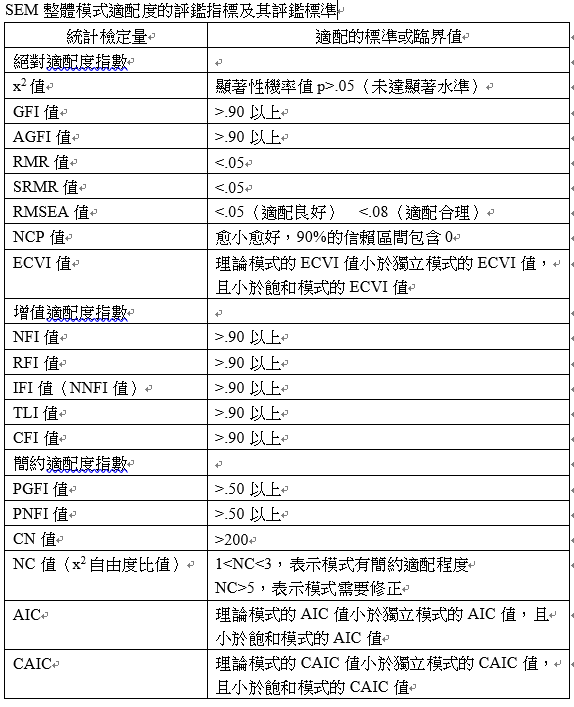
在SEM之驗證性因素分析中,純化指標測量模式通常很難達到合適,此時研究者可改為較為寬鬆策略,如增列測量殘差有相關,或增列其他潛在變項對指標變項影響的路徑。因為測量模式可以識別並不表示此測量模式與樣本資料可以有效契合,純化指標變項測量模式可能較難達到模式合適的標準(吳明隆,2019,p116)。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
陳寬裕、王正華(2022)。結構方程模型:運用AMOS分析。五南。
結構方程模型又稱為共變異數結構分析或線形結構方程,它是一種運用統計學中假設檢定概念,對有關變數的內在因素結構與變數間的因果關係進行驗證、分析的一種統計方法。由於結構方程模型對於潛在變數、測量誤差和因果關係模型皆具有獨特的處理能力,除了在心理學、教育學等領域的應用日臻成熟和完善之外,還不斷的被應用在其他多個領域(陳寬裕、王正華,2022,p2)。
結構方程模型是種能對潛在變數間之因果關係進行分析與假設檢定的一種統計方法。且是近年來在社會科學領域中發展最快速,應用愈來愈廣泛的一種多變量統計方法(陳寬裕、王正華,2022,p16)。
陳寬裕、王正華(2022:16~19)認為結構方程模型可以分為測量模型與結構模型兩部分,測量模型用以描述潛在變數與指標變數之間的關係,而結構模型則用以描述潛在變數之間的因果關係。由於社會科學領域中,一般研究者所關注的議題,大都屬於不能準確、直接測量的潛在變數(如:滿意度、忠誠度……),但潛在變數是可以研究的,方法是透過測量與潛在變數相關的觀察變數作為其指標變數,而對其間接地加以評價,而觀察變數通常是指問卷中的每一個題項。
修正指數(modification indices,MI)是Amos提供修正結構方程模型的修正指標,MI所代表的意義是一個被固定或限制住的參數被恢復成自由時,卡方值可能減少的最小的量,使用修正指數修改假設模型時,要從具有最大修正指數的參數開始修改,因為當模型對資料的配適程度愈好,卡方值就會愈小(陳寬裕、王正華,2022,p303、p304)。

拾參、中介變數與干擾變數
陳寬裕、王正華(2022)。結構方程模型:運用AMOS分析。五南。
中介變數(mediator)在心理、教育、社會和管理等研究中扮演重要的角色。如果自變數 X 透過某一變數 M 對依變數 Y 產生一定的影響,則稱 M 為 X 和 Y 的中介變數或 M 在 X 和 Y 的關係間扮演著中介角色(具有中介效果)。在中介變數被引入之下,若自變數對依變數之影響程度變為0,則稱該中介變數具有完全中介效果;若自變數對依變數之影響效果只是減弱而已,但仍具顯著性,則稱該中介變數具有部分中介效果(陳寬裕、王正華,2022,p316、p317)。
干擾變數又稱為調節變數或情境變數,它是指會影響自變數與依變數之間關係的方向或強度的變數。它可以是質性的(例如:性別、種族……)或是量化的(例如:薪資……)

拾肆、卡方檢定
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用。五南。
當資料變數的屬性為類別資料(名目尺度)時,我們常利用卡方檢定來做分析。因為卡方檢定的本質在於檢測資料所占的「比例」或「相對次數」(陳寬裕、王正華,2021,p285)。

參考文獻
林清山(2001)。心理與教育統計學(初版十一刷)。東華。
李茂能(2009)。圖解AMOS在學術研究之應用(初版一刷)。五南。
黃芳銘(2009)。結構方程模式-理論與應用(五版二刷)。五南。
張偉豪(2011)。SEM論文寫作不求人(一版)。鼎茂。
吳明隆、張毓仁(2011)。SPSS(PASW)與統計應用分析I、II(初版一刷)。五南。
涂金堂(2012)。量表編製與SPSS(初版一刷)。五南。
張偉豪、鄭時宜(2012)。與結構方程模型共舞-曙光初現(一版)。前程。
陳正昌(2013)。SPSS與統計分析(初版一刷)。 五南。
邱皓政(2015)。量化研究與統計分析:SPSS(PASW)資料分析範例解析(五版九刷)。五南。
凃金堂(2015)。SPSS與量化研究(二版一刷)。五南。
陳寬裕(2017)。應用統計分析:SPSS的運用(初版一刷)。五南。
吳明隆(2019)。結構方程式:AMOS的操作與應用(二版四刷)。五南。
陳寬裕、王正華(2021)。論文統計分析實務:SPSS與AMOS的運用(四版一刷)。五南。
陳寬裕、王正華(2022)。結構方程模型:運用AMOS分析(初版二刷)。五南。



發表迴響